
남궁성님의 자바의 정석 강의를 듣고 정리한 글입니다.
11장. 컬렉션 프레임워크(collections framework)
컬렉션 ( collection )
여러 객체 ( 데이터 ) 를 모아 놓은 것을 의미
프레임웍 ( framework )
표준화, 정형화된 체계적인 프로그래밍 방식
컬렉션 프레임워크 ( collections framework )
- 컬렉션 (다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
- 컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 클래스를 제공
- java.util 패키지에 포함.
컬렉션 클래스
다수의 데이터를 저장할 수 있는 클래스 ( Vector, ArrayList, HashSet )
| 인터페이스 | 특징 |
| List | 순서가 있는 데이터의 집합, 데이터의 중복을 허용한다 ex) ArrayList, LinkedList, Stack, Vector 등 |
| Set | 순서를 유지하지 않는 데이터의 집합, 중복을 허용하지 않는다 ex) HashSet, TreeSet |
| Map | key와 value의 쌍으로 이루어진 데이터의 집합. ex ) HashMap, TreeMap, HashTable, Properties 등 |
ArrayList
- ArrayList는 기존의 Vector을 개선한 것으로 구현원리가 기능적으로 동일
- ArrayList와 달리 Vector는 자체적으로 동기화처리 되어있음.
- List인터페이스를 구현하므로, 저장순서가 유지되고 중복을 허용한다.
- 데이터의 저장공간으로 배열을 사용한다
ArrayList 에 저장된 객체의 삭제과정


public class ArrayListTest {
@Test
void ArrayTest(){
List<Integer> test = new ArrayList<>();
test.add(0);
test.add(1);
test.add(2);
test.add(3);
test.add(4);
test.add(5);
test.add(6);
for (int i = 0; i<test.size(); i++) {
test.remove(i);
}
System.out.println("test = " + test);
}
@Test
void ArrayTest2(){
List<Integer> reverse = new ArrayList<>();
reverse.add(0);
reverse.add(1);
reverse.add(2);
reverse.add(3);
reverse.add(4);
reverse.add(5);
reverse.add(6);
for (int i = reverse.size() -1 ; i>=0 ; i--) {
reverse.remove(i);
}
System.out.println("reverse = " + reverse);
}
}
테스트결과
test = [1, 3, 5]
reverse = []
실제로 for문 방식으로 삭제하는 경우
마지막 값부터 삭제하느냐, 첫번째 값부터 삭제하느냐에 따라 결과값의 차이가 존재한다.
ArrayList 배열의 장단점

장점 : 배열은 구조가 간단하고 데이터를 읽는데 걸리는 시간이 짧다
단점1 : 크기를 변경할 수 없다.
- 크기를 변경해야되는 경우 새로운 배열을 생성 후 데이터를 복사해야됨
- 크기변경을 피하기 위해 충분히 큰 배열을 생성하면, 메모리가 낭비됨
단점2 : 비순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다.
- 데이터를 추가하거나 삭제하기 위해, 다른 데이터를 옮겨야함
- 그러나 순차적인 데이터 추가 (끝에 추가) 와 삭제 (끝부터 삭제)는 빠르다
LinkedList - 배열의 단점을 보완
배열과 달리 LinkedList는 불연속적으로 존재하는 데이터를 연결한다.


ArrayList LinkedList 성능비교
Arraylist 빠른 부분
- 순차적으로 데이터를 추가 삭제
- 접근시간
LinkedList가 빠른 부분
- 비순차적으로 데이털르 추가 삭제
| 컬렉션 | 읽기 | 추가/삭제 | 비고 |
| ArrayList | 빠르다 | 느리다 | 순차적 추가 삭제 빠름 비효율적 메모리 사용 |
| LinkedList | 느리다 | 빠르다 | 데이터 많을수록 접근성 떨어짐 |
스택 ( Stack )
- LIFO 구조
- 수식계산, 수식괄호검사, 앞으로 뒤로
큐 ( Queue )
- FIFO 구조
- 최근사용문서, 인쇄작업대기목록, 버퍼
Queue의 변형 - Deque, PriorityQueue, BlockingQueue
덱( Deque )
스택과 큐의 결합, 양끝에서 저장(offer), 삭제(poll) 가능
구현 클래스 : ArrayDeque, LinkedList

우선순위 큐 ( PriorityQueue )
우선순위가 높은것부터 꺼냄 (null 저장 x)
블락킹 큐 ( BlockingQueue )
비어 있을 때 꺼내기와, 가득 차 있을 때 넣기를 지정된 시간동안 지연시킴(block) - 멀티쓰레드
Enumeration , Iterator, ListIterator
컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
Enumeration은 Iterator 의 구버전
ListIterator는 Iterator의 접근성을 향상시킨 것 (단방향 -> 양방향)
Iterator
컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 것
컬렉션에 iterator()을 호출해서 Iterator을 구현한 객체를 얻어서 사용
ListIterator
Iterator의 기능을 확장 (상속)

Iterator 의 접근성을 향상시킴 ( 단방향 -> 양방향 )
ListIterator() 을 통해 얻을 수있다. ( List를 구현한 클래스에 존재)

HashSet 과 Tree Set
HashSet
Set인터페이스를 구현한 대표적 컬렉션 클래스
순서를 유지하려면 LinkedHashSet 사용하면된다.
TreeSet
범위 검색과 정렬에 유리한 컬렉션 클래스
HashSet보다 데이터 추가, 삭제에 시간이 더 걸린다.
HashSet
- 객체 저장 전에 기존에 같은 객체가 있는지 확인한다.
- 같은 객체가 없으면 저장하고, 있으면 저장하지 않는다.
- boolean add(Object o)는 저장할 객체의 equals와 hashCode()를 호출
equals와 hashCode()가 오버라이딩 되어있어야 한다.
예시)
public class HashTest {
public static void main(String[] args) {
Set<Person> personSet = new HashSet<>();
Person first = new Person("1", 10);
Person second = new Person("1", 10);
personSet.add(first);
personSet.add(second);
System.out.println("personSet = " + personSet);
}
}public class Person{
String name;
int age;
public Person (String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}실행 결과
personSet = [Person{name='1', age=10}, Person{name='1', age=10}]
Person에 equals와 hashCode를 Override 한 경우 결과 차이.
public class Person{
String name;
int age;
public Person (String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object obj)
{
if(!(obj instanceof Person)) {
return false;
}
Person tmp = (Person)obj;
return this.name.equals(tmp.name) && this.age == tmp.age;
}
@Override
public int hashCode(){
return (name+age).hashCode();
}
실행결과
personSet = [Person{name='1', age=10}]
TreeSet
- 범위 검색과 정렬에 유리한 이진검색 트리 (binary serch tree) 로 구현
- 이진 트리는 모든 노드가 최대 두개의 하위 노드를 가짐
- 이진검색 트리는 부모보다 작은값은 왼쪽 큰값은 오른쪽에 저장
- HashSet보다 데이터 추가, 삭제에 시간이 더 걸림

TreeSet에 7,4,9,1,5 순서로 데이터를 저장하면 위의 과정을 거친다.
HashMap과 TreeMap
순서 무작위, 중복(키중복 불가능, 값중복 가능)
HashMap(동기화 불가)은 HashTable(동기화 가능)의 신버전
HashMap
- Map인터페이스를 구현한 대표적 컬렉션 클래스
- 순서유지 필요 시 LinkedHashMap 클래스 사용하면됨
- 해싱 기법으로 데이터를 저장. 데이터가 많아도 검색이 빠르다.
- Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
TreeMap
- 범위 검색과 정렬에 유리한 클래스
- HashMap보다 데이터 추가 삭제에 시간이 더 걸린다.
- 이진 검색 트리의 구조로 키와 값의 쌍으로 이루어진 데이터를 저장
- TreeSet 처럼, 데이터를 정렬(키) 해서 저장하기 때문에 저장시간이 길다.
- 다수의 데이터에서 개별적인 검색은 TreeMap 보다 HashMap이 빠르다.
Map이 필요할 때 주로 HashMap 사용, 정렬이나 범위검색 필요 시 TreeMap 사용
Properties
- 내부적으로 HashTable 사용하며 key와 value를 (String,String) 저장.
- 내부 어플리케이션 환경설정에 관련된 속성을 저장하는데 사용되며,
파일로부터 값을 읽고 쓸 수 있는 메서드 제공한다.
Collections
컬렉션을 위한 메서드(Static) 를 제공
1. 컬렉션 채우기 복사 정렬 검색
fill(), copy(), sort(), binarySearch() 등
2. 컬렉션의 동기화 - SynchronizedXXX()
Collection, List, Set, Map, SortedSet, SortedMap ... 사용 가능하다.
java.util.Collections 내부
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
private static final long serialVersionUID = 3053995032091335093L;
final Collection<E> c; // Backing Collection
final Object mutex; // Object on which to synchronize
SynchronizedCollection(Collection<E> c) {
if (c==null)
throw new NullPointerException();
this.c = c;
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) {
this.c = c;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return c.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return c.isEmpty();}
}
public boolean contains(Object o) {
synchronized (mutex) {return c.contains(o);}
}
public Object[] toArray() {
synchronized (mutex) {return c.toArray();}
}
public <T> T[] toArray(T[] a) {
synchronized (mutex) {return c.toArray(a);}
}
public Iterator<E> iterator() {
return c.iterator(); // Must be manually synched by user!
}
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
public boolean remove(Object o) {
synchronized (mutex) {return c.remove(o);}
}
public boolean containsAll(Collection<?> coll) {
synchronized (mutex) {return c.containsAll(coll);}
}
public boolean addAll(Collection<? extends E> coll) {
synchronized (mutex) {return c.addAll(coll);}
}
public boolean removeAll(Collection<?> coll) {
synchronized (mutex) {return c.removeAll(coll);}
}
public boolean retainAll(Collection<?> coll) {
synchronized (mutex) {return c.retainAll(coll);}
}
public void clear() {
synchronized (mutex) {c.clear();}
}
public String toString() {
synchronized (mutex) {return c.toString();}
}
private void writeObject(ObjectOutputStream s) throws IOException {
synchronized (mutex) {s.defaultWriteObject();}
}
}
3. 변경불가 (readOnly) 컬렉션 만들기 - unmodifiableXXX()
Collection, List, Set, Map, NavigableSet, SortedSet, NavigableMap, SortedMap 사용 가능
java.util.Collections 내부
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c) {
return new UnmodifiableCollection<>(c);
}
4. 싱글톤 컬렉션 만들기 - singletonXXX()
List, Set, Map 사용 가능
java.util.Collections 내부
public static <T> Set<T> singleton(T o) {
return new SingletonSet<>(o);
}
public static <T> List<T> singletonList(T o) {
return new SingletonList<>(o);
}
public static <K,V> Map<K,V> singletonMap(K key, V value) {
return new SingletonMap<>(key, value);
}
12장. 제네릭스, 열거형, 어노테이션
제네릭스 ( Generics) 란
컴파일시 타입을 체크해주는 기능
객체의 타입 안정성을 높이고 형 변환의 번거로움을 줄여줌
제네릭 클래스의 선언
클래스를 작성 시 Object 타입 대신 T와 같은 타입변수를 사용
public class Box {
Object item;
public void setItem(Object item) {
this.item = item;
}
Object getItem() {
return item;
};
}
public class GenericBox<T> {
T item;
void setItem (T item) {
this.item = item;
}
T getItem() {
return item;
}
}Box 클래스를 GenericBox 로 변경 가능하다.
GenericBox<T> 제너릭 클래스, 'T의 GenericBox' 또는 'T GenericBox' 라고 읽는다
T : 타입변수 또는 타입 매개변수
GenericBox : 원시타입(raw type)
public class BoxTest {
public static void main(String[] args) {
GenericBox<String> box = new GenericBox<>();
//box.setItem(new Object()); // 오류발생
box.setItem("ABC");
String item = (String)box.getItem();
}
}
제약사항
static 멤버에는 타입변수 T 사용 할수 없다.
public class GenericBox<T> {
T item;
staic T item; //에러
static int compare(T t1, T t2){ //에러
...
}
}
제네릭 타입의 배열 T [] 를 생성하는것은 허용되지 않는다.
public class GenericBox<T> {
T item;
T[] itemArray;
T[] toArray(){
T[] tmpArr = new T [itemArray.length]; //에러 . 제네릭 배열 생성불가
...
}
}
제네릭 클래스의 객체 생성과 사용
제네릭 클래스의 선언
public class Box<T> {
T item;
void setItem (T item) {
this.item = item;
}
T getItem() {
return item;
}
}제네릭 클래스의 객체 생성 . 참조변수와 생성자에 대입된 타입 일치필요.

두 제네릭 클래스가 상속관계이고 대입된 타입이 일치하는 경우 사용 가능
Box<Apple> appleBox = new FruitBox<Apple>();
Box<Apple> appleBox = new Box<>;대입된 타입과 다른타입의 객체는 추가할 수 없다.

제한된 제네릭 클래스
- 제네릭 타입에 'extends'를 사용하면 특정 타입의 자손들만 대입할 수 있게 제한 가능
- add()의 매개변수 타입 T 도 자손타입이 될 수 있다.
- 인터페이스의 경우에도 implements가 아닌 extends를 사용한다.
와일드카드 '?'
제네릭 타입에 와일드 카드를 쓰면, 여러 타입을 대입 가능하다.
단 와일드 카드에는 <? extends T & E>와 같이 '&'를 사용불가하다.
<? extends T> // 와일드카드의 상한 제한 T와 자손들만 가능
<? super T> // 와일드 카드의 하한 제한 T와 그 조상만 가능
<?> // 제한없음, 모든 타입가능
제네릭 메서드
반환타입 앞에 제네릭 타입이 선언된 메서드
static <T> void sort (List<T> list, Comparator<? super T> c)클래스의 타입 매개변수<T> 와 메서드의 타입 매개변수 <T>는 별개
class FruitBox<T> {
static <T> void sort (List<T> list, Comparator<? super T> c)
}제네릭 메서드를 호출할 때 , 타입변수에 타입을 대입하여야 한다.
(대부분의 경우, 추정이 가능하므로 생략 가능)
FruitBox<Fruit> fruitBox = new FruitBox<Fruit> ();
FruitBox<Apple> appleBox = new FruitBox<Apple> ();
System.out.println(Juicer.<Fruit>makeJuice(fruitBox));
System.out.println(Juicer.makeJuice(appleBox));
제네릭 타입의 형변환
- 제네릭 타입과 원시 타입간 형변환 불가능
- 와일드 카드가 사용된 제네릭 타입으로는 형변환 가능
- <? extends Object>를 줄여서 <?> 로 쓸 수 있다.
열거형 (enums)
관련된 상수들을 묶어놓은 것, Java는 타입에 안전한 열거형을 제공
열거형 정의 방법
enum 열거형이름 {상수명, 상수명1, 상수명2 ...}
열거형에 멤버 추가하기
public enum Direction {
EAST(1),
SOUTH(5),
WEST(-1),
NORTH(10);
private final int value; // 정수를 저장할 필드 추가
Direction(int value){ // 생성자를 추가
this.value = value;
}
public int getValue() {
return value;
}
}
어노테이션 (Annotation)
주석처럼 프로그래밍 언어에 영향을 미치지 않으며 유용한 정보를 제공
Java에서 제공하는 어노테이션
| 어노테이션 | 설명 |
| @Override | 컴파일러에게 오버라이딩하는 메서드라는걸 알림 |
| @Deprecated | 앞으로 사용하지 않을것을 권장하는 메서드에 붙임 |
| @SuppressWarnings | 컴파일러의 특정 경고메시지가 나타나지 않게 해줌 |
| @SafeVarargs | 제네릭 타입의 가변인자에 사용( jdk1.7이후) |
| @FunctionalInterface | 함수형 인터페이스라는것을 알린다( jdk1.8이후) |
| @Native | native메서드에서 참조되는 상수 앞에 붇인다.( jdk1.8이후) |
| @Target | 어노테이션이 적용가능한 대상을 지정하는데 사용한다. |
| @Documented | 어노테이션 정보가 javadoc으로 작성된 문서에 포함되게 한다 |
| @Inherited | 어노테이션이 자손 클래스에 상속되도록 한다 |
| @Retention | 어노테이션이 유지되는 범위를 지정하는데 사용한다 |
| @Repeatable | 어노테이션을 반복해서 적용할 수 있게 한다( jdk1.8이후) |
배경색이 적용된 어노테이션은 메타 어노테이션이다.
메타 어노테이션이란 : 다른 어노테이션에서도 사용되는 어노테이션의 경우를 말하며,
custom 어노테이션을 생성할때 주로 사용한다.
마커 어노테이션
어노테이션 요소의 규칙
- 요소타입은 기본형, String, enum, 어노테이션, Class만 허용된다
- 괄호()안에 매개변수를 선언할 수 없다.
- 예외를 선언할 수 없다.
- 요소를 타입 매개변수로 정의할 수 없다.
@interface AnnoTest {
int id = 100; // OK. 상수 선언
String major(int i, int j); // 에러. 매개변수를 선언할 수 없음
String minor() throws Excetpion; // 에러. 요소를 선언할 수 없음.
ArrayList<T> list(); // 에러. 요소의 타입에 타입 매개변수 사용 불가
}
13장. 쓰레드(thread)
프로세스 : 실행중인 프로그램 , 자원 과 쓰레드로 구성
쓰레드 : 프로세스 내에서 실제 작업을 수행, 모든 프로세스는 하나의 쓰레드를 가지고 있다.
멀티 태스킹 : 동시에 여러 프로세스를 실행시키는것
멀티 쓰레딩 : 하나에 프로세스 내에 동시에 여러 쓰레드를 실행시키는 것
- 프로세스를 생성하는 것보다 쓰레드를 생성하는 비용이 적다
- 같은 프로세스 내의 쓰레드들은 서로 자원을 공유한다.
멀티쓰레드의 장단점
장점
- 시스템 자원을 효율적으로 사용 가능
- 사용자에 대한 응답성 (responseness)이 향상
- 코드가 간결해진다
단점
- 동기화(syncronization)에 주의해야한다.
- 교착상태(dead-lock)가 발생하지 않도록 주의해야 한다.
- 각 쓰레드가 효율적으로 고르게 실행될 수 있게 해야 한다.
쓰레드의 구현과 실행
- Thrad 클래스를 상속
- Runnable 인터페이스를 구현

멀티스레드는 동시에 두 작업이 번갈아 수행이 되지만
Context Switching 시간이 소요되므로 싱글스레드보다 멀티스레드가 더 시간이 걸릴 수 있다.
시간이 더 걸리더라도 동시에 작업을 할 수 있는게 멀티스레드의 장점이다.
쓰레드의 우선순위 (priority of thread)
작업의 중요도에 따라 쓰레드의 우선순위를 다르게 하여 쓰레드가 더 많은 작업시간을 갖게 할 수 있습니다.
쓰레드 그룹 (ThreadGroup)
- 서로 관련된 쓰레드를 그룹으로 묶어서 다루기 위함 (보안상 목적)
- 모든 쓰레드는 반드시 하나의 쓰레드 그룹에 포함되어 있어야 한다
- 쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 'main 쓰레드 그룹' 에 속함
- 자신을 생성한 쓰레드 (부모 쓰레드)의 그룹과 우선순위를 상속받는다.
데몬쓰레드 (daemon thread)
일반 쓰레드(non-deamon thread)의 작업을 돕는 보조적인 역할을 수행
일반 쓰레드가 모두 종료되면 자동적으로 종료된다.
가비지 컬렉터, 자동저장, 화면자동갱신 등에 사용된다.
무한루프와 조건문을 이용해서 실행 후 대기하다가 특정조건이 만족되면 작업을 종료하고 다시 대기하도록 작성한다.
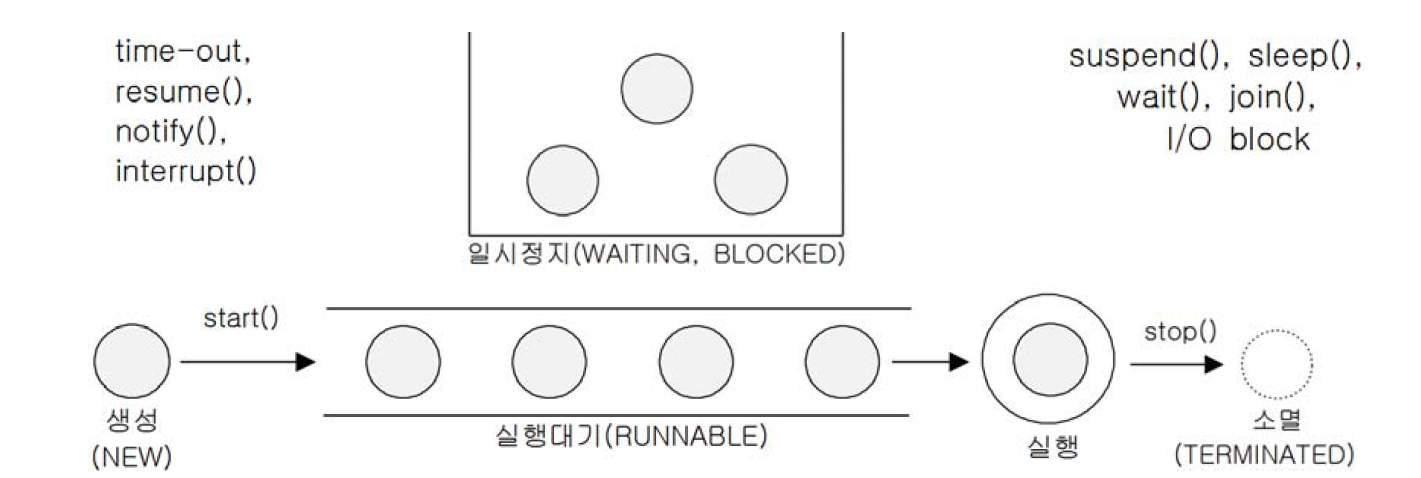
쓰레드의 상태
| 상태 | 설명 |
| NEW | 쓰레드가 생성되고 아직 start()가 호출되지 않은 상태 |
| RUNNABLE | 실행중 또는 실행 가능한 상태 |
| BLOCKED | 동기화 블럭에 의해 일시정지된 상태 (lock 이 풀릴때까지 기다리는 상태) |
| WAITING, TIMED_WAITING |
쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은(unrunnable) 일시정지 상태, TIMED_WAITING은 일시정지시간이 지정된 경우를 의미한다 |
| TERMINATED | 쓰레드의 작업이 종료된 상태 |
쓰레드의 동기화 - synchronized
class Ex13_12 {
public static void main(String args[]) {
Runnable r = new RunnableEx12();
new Thread(r).start(); // ThreadGroup에 의해 참조되므로 gc대상이 아니다.
new Thread(r).start(); // ThreadGroup에 의해 참조되므로 gc대상이 아니다.
}
}
class Account {
private int balance = 1000;
public int getBalance() {
return balance;
}
public synchronized void withdraw(int money){
if(balance >= money) {
try { Thread.sleep(1000);} catch(InterruptedException e) {}
balance -= money;
}
} // withdraw
}
class RunnableEx12 implements Runnable {
Account acc = new Account();
public void run() {
while(acc.getBalance() > 0) {
// 100, 200, 300중의 한 값을 임으로 선택해서 출금(withdraw)
int money = (int)(Math.random() * 3 + 1) * 100;
acc.withdraw(money);
System.out.println("balance:"+acc.getBalance());
}
} // run()
}
synchronized 없을때 실행결과
balance:400
balance:700
balance:100
balance:100
balance:100
balance:0
balance:-100synchronized 있을때 실행결과
balance:900
balance:600
balance:500
balance:400
balance:200
balance:0
balance:0
wait(), notify(), notifyAll()을 이용한 동기화
동기화의 효율을 높이기 위해 wait(), notify()를 사용
Object 클래스에 정의되어 있으며, 동기화 블록 내에서만 사용할 수 있다.
wait() - 객체의 lock을 풀고 쓰레드를 해당 객체의 waiting pool에 넣는다.
notify() - waiting pool 에서 대기중인 쓰레드 중에 하나를 깨운다.
notifyAll() - waiting pool에서 대기중인 모든 쓰레드를 깨운다
14장. 람다와 스트림 (Lambda & Stream)
람다식이란?
- 함수를 간단한 식으로 표현하는 방법
- 익명함수
함수와 메서드의 차이
- 근본적을 동일, 함수는 일반적 용어 , 메서드는 객체지향 개념 용어
- 함수는 클래스에 독립적, 메서드는 클래스에 종속적
주의사항
- 메개변수 하나인 경우, 괄호 생략가능
- 블록안의 문장이 하나뿐 일 때, 괄호{} 생략가능
- 하나뿐인 문장이 return문이면 괄호{} 생략불가
함수형 인터페이스
람다식은 익명 객체
함수형 인터페이스 - 단 하나의 추상 메서드만 선언된 인터페이스
함수형 인터페이스 예제
public class Car {
private static final int RULE_FORWARD = 4;
private static final int RULE_MAX_RANGE = 9;
private RandomUtil randomUtil;
private CarName carName;
private int position;
public Car(Car car) {
this.carName = car.carName;
this.position = car.position;
this.randomUtil = car.randomUtil;
}
public Car(String name, int position, RandomUtil randomUtil) {
this.carName = new CarName(name);
this.position = position;
this.randomUtil = randomUtil;
}
public void tryMove() {
if (isMovable()) {
move();
}
}
private boolean isMovable() {
return RULE_FORWARD < randomUtil.randomNumber(RULE_MAX_RANGE);
}
private void move() {
position++;
}
public String getName() {
return carName.getCarName();
}
public int getPosition() {
return position;
}
@Override
public String toString() {
return "Car{" +
"randomUtil=" + randomUtil +
", name='" + carName + '\'' +
", position=" + position +
'}';
}
}
@FunctionalInterface
public interface RandomUtil {
int randomNumber(int bound);
}
public class RandomNumber implements RandomUtil {
private static final Random random = new Random();
@Override
public int randomNumber(int bound)
{
return random.nextInt(bound + 1);
}
}
new Car(errorCarName, 0 , new RandomNumber())
메서드 참조 (method reference)
Integer method(String s) {
return Integer.parseInt(s);
}
Function<String,String> f = (String s) -> Integer.parseInt(s);
Function<String,String> f = Integer::parseInt //메서드 참조
생성자의 메서드 참조
Supplier<MyClass> s = () => new MyClass();
Supplier<MyClass> s = MyClass::new;
배열의 메서드 참조
Function<Integer, int[]> f = x -> new int[x];
Function<Integer, int[]> f2 = int[]::new;
스트림 (Stream)이란?
다양한 데이터 소스를 표준화된 방법으로 다루기 위한 것
스트림이 제공하는 기능 - 중간연산과 최종연산
Computer Science : A sequence of data elements made available over time
(시간이 지남에 따라 이용할 수 있게 된 일련의 데이터 요소들)
Common nouns : A continuous flow of things or people
(사물이나 사람의 연속적인 흐름)
특징
- 스트림은 데이터 소스로부터 읽기만 할 뿐 변경하지 않는다.
- 스트림은 Iterator처럼 일회용이다.
- 최종연산 전까지 중간연산 수행되지 않는다. - 지연연산
- 스트림은 작업 내부를 반복으로 처리한다
- 작업을 병렬로 처리 - 병렬 스트림
- 기본형 스트림 - IntStream, LongStream, DoubleStream
람다식을 소스로 하는 스트림 생성하기
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) // 이전 요소에 종속적
static <T> Stream<T> generate(Supplier<T> s) // 이전 요소에 독립적예시)
Stream<Integer> evenStream = Stream.iterate(0, n->n+2);
Stream<Double> randomStream = Steram.generate(Math::random);
Stream<Integer> oneStream = Stream.generate(()->1);
스트림의 중간연산
스트림 자르기 - skip(), limit()
Stream<T> skip(long n) //앞에서부터 n개 건너뛰기
Stream<T> limit(long maxSize) // maxSize 이후 요소는 잘라냄
IntSteam intStream = IntStream.rangeClosed(1, 10); //1,2,3,4,5,6,7,8,9,10
intStream.skip(3).limit(5).foreach(System.out::print); //4,5,6,7,8
스트림 요소 걸러내기 - filter(), distinct()
Stream<T> filter(Predicate<? super T> predicate);
Stream<T> distinct();
@Test
void test4(){
IntStream.iterate(0, i->(i+1) % 2)
.distinct()
.limit(10)
.forEach(System.out::println);
System.out.println(" Complete");
}결과
0, 1 출력 이후 무한루프
distinct 입장에서 반복해서 들어오는 0과 1이라는 값은 이미 발견한 적이 없는 값이므로 limit으로 넘겨주지 않는다.
@Test
void test5(){
IntStream.iterate(0, i->(i+1) % 2)
.limit(10)
.distinct()
.forEach(System.out::println);
System.out.println(" Complete");
}결과
0, 1 출력 이후 complete
먼저 limit 제한이 걸리기 때문에 다음 distinct로 넘어갈 수 있다.
다른 연산이 한 과정으로 병합되는것을 루프 퓨전(loop fusion)이라고 한다.
스트림을 사용하는 경우 스트림 내부에서 연산이 일어나기 때문에 (내부반복)
코드가 정상적으로 동작하지 않을 경우
내부가 어떻게 동작하는지 명확히 알고 사용해야된다.
스트림 정렬 - sorted()
Stream<T> sorted() // 스트림요소의 기본 정렬(Comparable)로 정렬
Stream<T> sorted(Comparator<? super T> comparator // 지정된 Comparator 로 정렬
스트림의 요소 변환하기 - map()
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
스트림을 기본 스트림으로 변환
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
스트림의 스트림을 스트림으로 변환 - flatMap()
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
Stream<Stream<String>> strStrStrm = strArrStrm.map(Arrays::stream);
Stream<String> strStrStrm = strArrStrm.flatMap(Arrays::stream);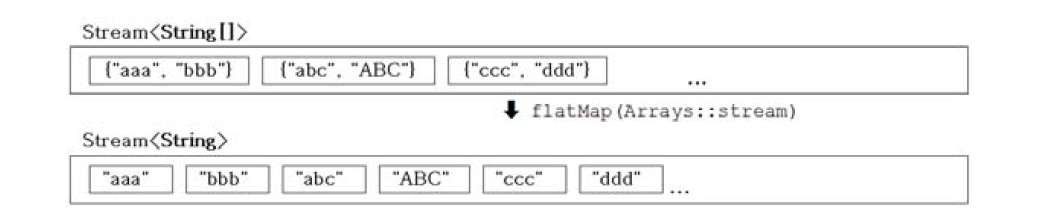
스트림의 요소를 소비하지 않고 엿보기 - peek()
Stream<T> peek(Consumer<? super T> action); // 중간연산 (스트림을 소비 x)
void forEach(Consumer<? super T> action); // 최종연산 (스트림을 소비 o)
fileStream.map(File::getName) // Stream<File> -> Stream<String>
.filter(s -> s.indexOf('.') != -1) //확장자가 없는 것은 제외
.peek(s->System.out.printf("filename=%s%n", s)) // 파일명 출력
.map(s -> s.substring(s.indexOf('.') + 1)) //확장자만 추출
.peek(s -> System.out.printf("extention=%s%n", s) //확장자를 출력한다.
.forEach(System.out::println); //최종연산 스트림을 소비
Optional<T>와 OptionalInt
T 타입 객체의 래퍼클래스 Optional<T>
Optional<String> optVal = Optional.of(null); // NPE 발생
Optional<String> optVal = Optional.ofNullable(null); //okOptional 객체의 값 가져오기 - get(), orElse(), orEElseGet(), orElseThrow()
Optional<String> optVal = Optional.of("abc");
String str1 = optVal.get(); //null일 시 예외발생
String str2 = optVal.orElse(""); // null 일시 "" 반환
String str3 = optVal.of(String::new); //람다식 사용가능
String str4 = optVal.orElseThrow(NullPointerException::new); //널일 시 예외발생isPresent() - Optional 객체의 값이 널이면 false , 아니면 true 반환
스트림의 최종연산
스트림에 모든요소에 지정된 작업을 수행 - forEach, forEachOrdered()
- forEach는 대개 로그나 디버깅을 위한 출력으로 사용할 것을 권장한다.
- 스트림이 수행한 연산 결과를 보여줄 때 사용하고, 계산할 때는 사용하지 말자.
조건 검사 - allMatch(), anyMatch(), noneMatch()
boolean allMatch(Predicate<? super T> predicate); // 모든 요소가 조건을 만족시키면 true
boolean anyMatch(Predicate<? super T> predicate); // 한 요소라도 조건만족시키면 true
boolean noneMatch(Predicate<? super T> predicate); //모든 요소가 조건을 만족시키지 않으면 true
조건에 일치하는 요소 찾기 - findFirst(), findAny()
Optional<T> findFirst() //첫번째 요소를 반환, 순차 스트림에 사용
Optional<T> findAny() //아무거나 하나를 반환, 병렬 스트림에 사용
Optional<Student> result = stuStream.filter(s -> s.getTotalScore() <= 100).findFirst;
Optional<Student> result = parallelStream.filter(s -> s.getTotalScore() <= 100).findAny;
스트림의 요소를 하나씩 줄여가며 누적연산 수행 reduce()
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);- identity - 초기값
- accumulator - 이전 연산결과와 스트림의 요소에 수행할 연산
reduce()의 병렬처리
Stream.parallel()은 Stream연산을 병렬 처리로 수행하도록 한다.
즉 parallel()과 함께 reduce()를 사용하면 순차적 연산이 아닌
여러개의 연산 동시에 실행하고 그 작업을 다시 병합하여 최종적으로 1개의 결과를 생성한다.
ex) (1 + 2) + (3 + 4) + ... + ( 9 + 10 )
@Test
void test1(){
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.parallel().reduce(0, (total, n) -> total + n);
System.out.println("sum: " + sum);
}결과
sum: 55
하지만 빼기 연산의 경우 병렬처리는 예상했던 결과값과 다르다.
코드를 실행해보면 -55가 아니라 -5가 리턴된다
연산이 ( 1 -2 ) - ( 3 - 4 ) ... - ( 9 -10 ) 처럼 연산이 수행되면서 순차적으로 연산하는것과 다르기 때문이다.
@Test
void test2(){
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.parallel().reduce(0, (total, n) -> total - n);
System.out.println("sum: " + sum);
}
결과
sum: -5
따라서 병렬처리과정에서 reduce()를 사용할때 이런 문제가 없는지 확인이 필요하다.
병렬처리에서 reduce()는 순차적으로 처리
병렬처리에서 연산순서에 따라 발생하는 문제를 해결하기 위해 다른 규칙을 추가할 수 있다.
(total1,total2) -> total1 + total2 가 추가되었다.
해당 부분은 병렬로 처리된 결과들의 관계를 나타낸다.
첫번째 연산과 두번째 연산은 합해야 한다는 규칙을 추가한 것이다.
이렇게 규칙을 추가하면 첫번째 연산 결과가 다음 연산에 영향을 주기 대문에
reduce()는 작업을 나눠서 처리할 수 없게 된다.
@Test
void test3() {
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = numbers.reduce(0,
(total, n) -> total - n,
(total1, total2) -> total1 + total2);
System.out.println("sum: " + sum);
}결과
sum: -55
collect()와 Collectors
collect() : 그룹별로 나누어 리듀싱, Collector을 매개변수로 하는 스트림의 최종연산
Collector는 수집(collect) 에 필요한 메서드를 정의해 놓은 인터페이스이다.
public interface Collector<T, A, R> { //T 요소를 A에 누적한 다음, 결과를 R로 변환해서 반환
Supplier<A> supplier(); //누적할 곳 StringBuilder::new
BiConsumer<A, T> accumulator(); //누적 방법 sb.append(s)
BinaryOperator<A> combiner(); //결합방법(병렬) (sb1, sb2)->sb1.append(sb2)
Function<A, R> finisher(); //최종변환 sb-> sb.toString()
Set<Characteristics> characteristics(); //컬렉터의 특성이 담긴 Set 반환
...
}
Collectors 클래스는 다양한 기능의 컬렉터 (Collector을 구혆나 클래스)를 제공
변환 : mapping(), toList(), toMap(), toCollection()
통계 : counting(), summmingInt(),averagingInt(), maxBy(), minBy(), summarizingInt()
문자열 결합 : joining()
리듀싱 : reducing()
그룹화와 분할 : groupingBy(), partitioningBy(), collectingAndThen()
자바의 정석 요약집
https://youtube.com/playlist?list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp
자바의 정석 기초편(2020최신)
최고의 자바강좌를 무료로 들을 수 있습니다. 어떤 유료강좌보다도 낫습니다.
www.youtube.com
https://codechacha.com/ko/java8-stream-reduction/
Java - Stream.reduce() 사용 방법 및 예제
Stream.reduce(accumulator) 함수는 Stream의 요소들을 하나의 데이터로 만드는 작업을 수행합니다. Stream.reduce(init, accumulator) 처럼 초기 값을 인자로 전달할 수 있습니다. Stream.parallel()은 Stream 연산을 병렬
codechacha.com
'스터디 > 2023_스프링부트' 카테고리의 다른 글
| [study] 스프링MVC 정리 1 (0) | 2023.07.24 |
|---|---|
| [study] HTTP 웹 기본 지식 (1) | 2023.07.23 |
| [study] 자바의 정석 - chapter 6~9 (0) | 2023.07.09 |
| [study] http 멱등성 알아보자 (0) | 2023.07.03 |
| [study]Spring IOC와 DI (0) | 2023.06.26 |